Backtesting The Full Strategy Loop: How Not To Lie To Yourself
Time to read:
15min
This article picks up after the previous post on turning forecasts into target positions. If you have not read it yet, start here: https://x.com/structure_fi/status/2054876913848500509
At this point, the strategy has crossed an important line. It is no longer just asking, "What do we think happens next?" It is asking, "What would we have done, in order, through time?"
That is what a backtest is supposed to answer.
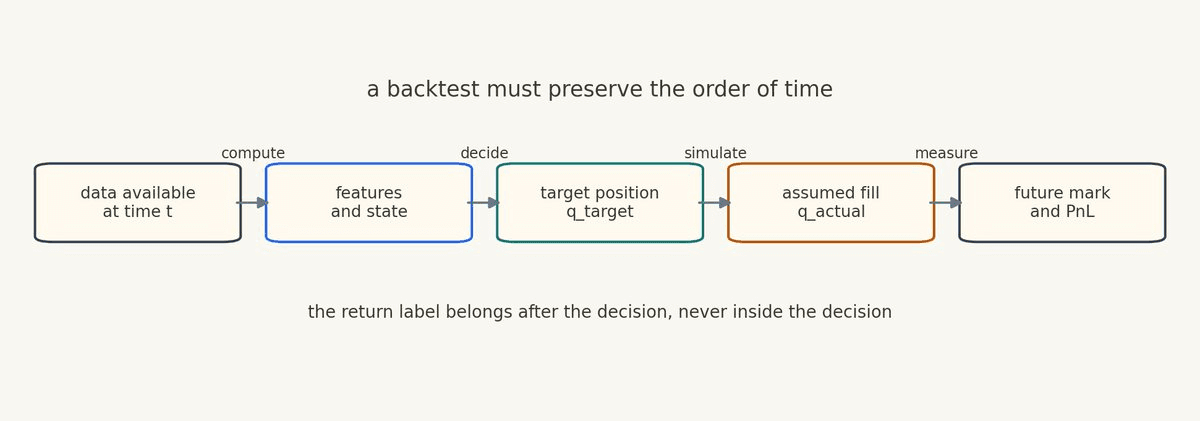
A real backtest is not mainly a test of whether the idea sounds plausible, whether the chart is visually satisfying, or whether a model has positive IC in a research table. It is a replay of what the strategy would have known, computed, decided, and held at each moment in history.
This is where a lot of systematic trading research quietly lies to itself.
The lie is rarely dramatic. It is usually small and boring. A feature is normalized using the full sample. A signal uses a bar close that would not have existed yet. A strategy assumes it moved into a new target position instantly. Costs are added after the fact with a number that makes the chart still look good. A state variable is recomputed independently on every row, even though the live strategy would have carried memory from the previous decision.
Each mistake feels minor. Together they turn a backtest into a story about a strategy that never could have existed.
The right standard is simple:
A backtest should replay the full strategy loop without violating time.
For Structure, this boundary matters. A strategy produces deterministic signals, state transitions, and target positions. The target executor sits outside the strategy logic and manages the work of moving toward those targets. That means the backtest should focus on the strategy decisions the user controls, while making fill, cost, slippage, delay, and achieved-position assumptions explicit.
You do not need user-facing order management to do honest backtesting. You do need honest assumptions about the gap between intended exposure and achieved exposure.
A Backtest Is A Time Machine With Rules
The first rule is that time only moves forward.
At time t, the strategy can use data available up to t. It cannot use the future return label. It cannot use a volatility estimate fit on the whole dataset. It cannot use tomorrow's liquidity to decide today's target position.
If D_{\leq t} is the data available through time t, then a causal feature should be a function of that history:
The future return target belongs after the decision:
The target r_t,h can be used to train and evaluate the model, but it cannot leak into x_t, the state transition, the target position, or the fill assumption at time t.
This sounds obvious until you inspect real research code.
The classic version is full-sample normalization. Someone computes the mean and standard deviation of a feature using the entire dataset, then trains on the early part and tests on the later part. The return label never directly touched the feature, so the mistake feels harmless. It is not harmless. The feature transformation has already learned something about the future distribution.
Another version is timestamp confusion. A strategy uses a bar's high, low, close, or volume to make a decision at the same bar's open. The backtest looks precise because every row is aligned. It is actually using information that arrives too late.
The cruel thing about these bugs is that they often improve the backtest just enough to keep the project alive. The strategy does not look magical. It just looks promising. That is why they survive.
Backtest The Policy, Not Just The Prediction
Prediction tests ask whether a forecast contains information.
Strategy backtests ask what the system would have done with that information.
Those are different questions.
A complete target-position backtest has this loop:
Here, x_t is the causal feature vector, hat r is the forecast, s_t is the strategy state, q_target is the desired exposure, q_actual is achieved exposure under the backtest assumption, and A_t contains assumptions about delay, fills, fees, slippage, funding, and venue constraints.
The important part is not the exact notation. The important part is that every step is explicit.
If your model forecast is good but your state machine churns, you need to see that. If your target positions look stable but assumed costs destroy the result, you need to see that. If the strategy only works when q_actual instantly equals q_target, you need to know before you trust it.
At trading firms, a lot of research dies at this stage. That is not failure. That is the process working. A backtest that kills a bad strategy early is saving you from learning the same lesson later with worse data, more complexity, and live risk.
Target Position Is Not Achieved Exposure
In Structure, the strategy output is a target position. The executor manages the mechanics of getting there outside of the strategy logic.
That is a clean product boundary. It lets strategy authors think in terms of data, computations, signals, state, and target positions instead of hand-writing order handling code.
But a backtest still has to model the gap between the target and the achieved exposure.
The simplest assumption is instant fill:
That assumption is sometimes useful as a first pass, but it is almost always too generous. A slightly more honest educational model allows the actual position to move toward the target over time:
Here, lambda_t is between 0 and 1. If lambda_t is 1, the strategy reaches the target immediately. If it is smaller, the actual position moves more slowly. In a real system, the effective value depends on liquidity, costs, venue conditions, position size, latency, and executor behavior.
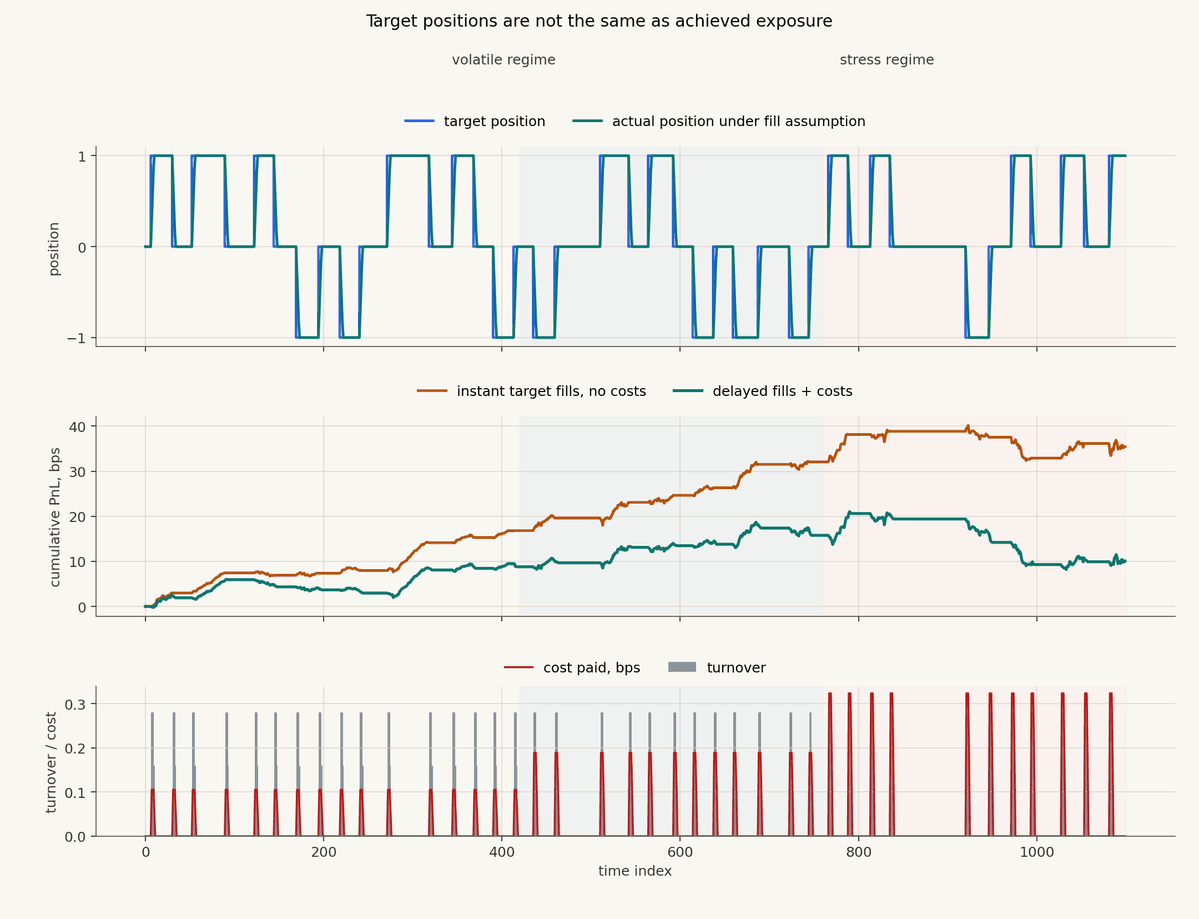
The chart is synthetic, but the lesson is real. The target-position backtest has one equity curve. The achieved-exposure backtest has another. The difference is not cosmetic. It is the part of the strategy that lives in the world.
Knight Capital in 2012 is a brutal reminder that intended logic and actual market exposure are not the same object. The issue was not that a forecast was wrong. The firm had a technology deployment failure in an automated router, kept sending erroneous child orders, and accumulated large unintended positions in roughly forty-five minutes. That is a production control story, not an argument that every strategy author should manage orders manually. The useful lesson for backtesting is narrower: actual exposure deserves to be measured separately from intended exposure.
If the backtest only tracks target positions, it may miss the most important operational question: what exposure would the strategy actually have carried under the assumptions we are making?
Costs Are A Model, Not A Footnote
Costs are not something you sprinkle on after the strategy works.
Costs are part of the strategy environment.
A simple cost model might look like this:
Here, Delta q_t is the position change, f_t can represent explicit fees or funding, a_t can represent spread and linear slippage, and the nonlinear term can represent market impact or worse fills for larger changes.
Then PnL is measured on achieved exposure after costs:
The exact cost model can be simple at first. What matters is that it is visible and stressable.
The most dangerous cost assumption is the one hidden in the code. If a backtest says final value, fees, and slippage were "calculated," you still want to know the assumptions. Did costs widen during volatile periods? Does cost scale with turnover? Is funding included? Are gas and venue fees included where relevant? Does the model punish excessive target-position changes?
The first time you add a realistic cost model to a strategy, it can feel like someone turned down the brightness on the entire idea. That is useful. Trading edge is usually small, and the market charges rent.
If the strategy only works before costs, it does not work yet.
Stress The Assumptions
A single backtest curve is not an answer. It is one observation under one set of assumptions.
You should rerun the same strategy under worse assumptions:
higher fees
wider spread
slower movement from target to actual position
delayed fills
worse marks during stress
missing data
tighter capacity
higher funding
lower liquidity in volatile regimes
This is not pessimism. It is calibration.
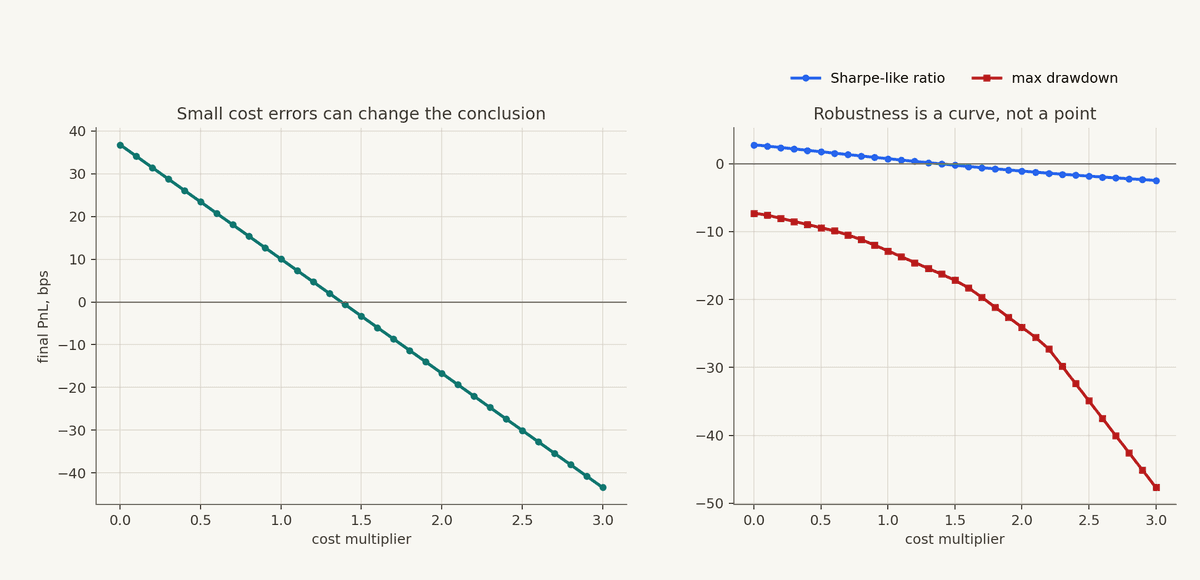
The cost-sensitivity curve is often more useful than the headline PnL. If a strategy is profitable only when costs are exactly right, you do not have much room for measurement error. If the strategy survives a range of reasonable assumptions, it is more interesting.
This is one of the practical lessons of Long-Term Capital Management. LTCM's trades were often based on relative-value relationships that looked rational in normal conditions. The problem was not that every relationship was intellectually stupid. The problem was leverage, crowding, liquidity, and a market environment where spreads that were expected to converge instead widened under stress. The fund's positions were not just exposed to expected value. They were exposed to the path required to survive until the expected value arrived.
Backtesting has the same issue at smaller scale. A strategy can be "right" in the long run and still fail under the path assumptions required to get there.
That is why stress tests should not be treated as optional decoration. They are where the backtest starts admitting uncertainty.
Stateful Strategies Need Stateful Backtests
A state machine cannot be backtested as if every row is independent.
The strategy carries memory:
current state
current target position
achieved position under the fill assumption
rolling feature statistics
cooldowns
warmup periods
unknown-regime flags
risk caps
previous fills and costs
versioned strategy parameters
That memory must be replayed exactly through time.
For example, a cooldown rule is meaningless if the backtest recomputes every row from scratch. A trailing volatility estimate is leaking if it sees future rows. An unknown_regime state is fake if the strategy continues opening new risk while the backtest label says it should have paused.
One useful engineering habit is to make every state transition auditable. At any timestamp, you should be able to ask:
What data was available?
What feature values were computed?
What state was the strategy in before the decision?
What transition fired?
What target position was emitted?
What achieved-position assumption was applied?
What cost was charged?
What PnL was marked?
If you cannot answer those questions, you do not have a backtest. You have a result file.
Break The Result By Regime
One equity curve hides too much.
Markets have regimes. A strategy can make money in calm periods, give it back in volatility, and become dangerous during stress. Or it can look mediocre overall while doing exactly what it is supposed to do in the narrow environment it was designed for.
So split the result:
calm versus volatile periods
high spread versus low spread
high volume versus low volume
normal funding versus extreme funding
in-distribution versus unknown-regime periods
long exposure versus short exposure
high turnover versus low turnover
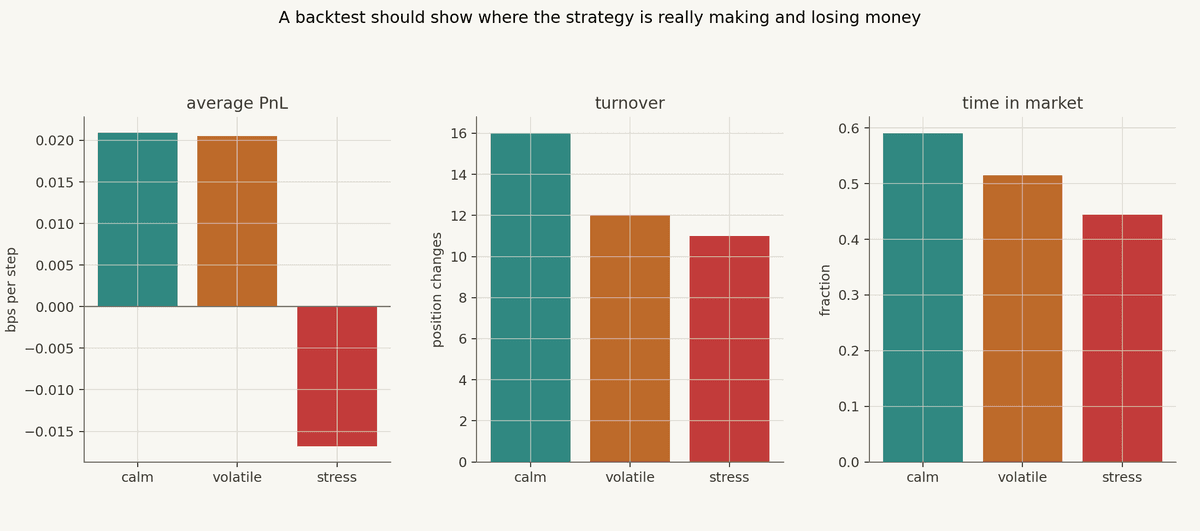
This is where the backtest becomes a research tool instead of a scoreboard.
The useful interpretation usually comes from the asymmetries. Maybe most of the PnL comes from one regime. Maybe turnover is highest exactly when costs are worst. Maybe the strategy spends too much time in market during stress, or maybe an unknown-regime filter gives up some participation while materially reducing drawdown. Those are not footnotes to the backtest; they are the backtest.
The goal is not to produce a perfect story. The goal is to expose the actual story.
Measure More Than Returns
Final PnL is a thin summary.
A useful backtest should report at least:
final value
drawdown
volatility
turnover
fees
slippage assumptions
funding
hit rate
average exposure
time in market
PnL by regime
PnL by state
PnL by long versus short exposure
worst days or worst windows
sensitivity to costs and delays
parameter sensitivity
Drawdown is usually more informative than people want it to be:
Turnover tells you how hard the strategy is asking the executor to work:
Parameter sensitivity tells you whether the result is robust or whether you found one lucky setting:
That last formula is dangerous if abused. If you sweep enough parameters, something will look good. The backtest should show the surface around the winner, not just the winner.
The best strategies usually do not appear as one miraculous point. They appear as a region where the idea behaves reasonably.
Version The Strategy You Backtested
This sounds administrative. It is not.
If a strategy changes, the backtest has to know which version produced which result. Otherwise you end up comparing ghosts.
At minimum, the backtest should be tied to:
strategy logic version
parameters
feature definitions
training window
validation window
cost assumptions
fill assumptions
data version
venue assumptions
benchmark version
This is one reason Structure's emphasis on versioned, auditable strategy logic matters. When a strategy is represented as deterministic data, computations, signals, state machines, and target positions, the backtest can be tied to the exact logic that produced the behavior.
That is how research becomes operational.
It is also how you avoid the classic research meeting where nobody can explain why last week's backtest is different from this week's backtest.
What Structure Should Make Easy
The user-facing strategy should stay focused on the pieces the user can reason about:
tick-level data
computations
signals
state transitions
target positions
parameters
versioned changes
backtests against benchmarks
The executor can remain outside the strategy logic. That is a clean abstraction. But the backtest still needs to report the consequences of its assumptions: fees, slippage, final value, achieved exposure, turnover, and sensitivity.
That combination is powerful.
It gives the user a strategy that is inspectable without forcing them to become an order-management engineer. It also avoids the opposite mistake: pretending that target positions magically become PnL without frictions.
The product promise should be speed with rigor. The backtest is where rigor shows up.
The Point
A backtest is not proof that a strategy will work.
It is a disciplined attempt to avoid fooling yourself.
Preserve time. Use causal features. Replay the full decision loop. Separate target positions from achieved exposure. Charge costs. Stress assumptions. Keep state. Break results by regime. Version everything.
If the strategy still looks good after that, it has earned more attention.
If it does not, the backtest did its job.
Not Financial Advice
The content above is for general educational and informational purposes only. It is not financial, investment, trading, legal, tax, accounting, or other professional advice, and it is not a recommendation, offer, or solicitation to buy, sell, hold, or use any asset, strategy, protocol, venue, or financial product.
Trading and automated strategies involve substantial risk, including the possible loss of principal. Crypto assets and DeFi markets can be highly volatile, illiquid, technically complex, and subject to execution, smart contract, custody, regulatory, and counterparty risks. Past performance, backtests, simulations, or examples do not guarantee future results.
You are responsible for your own decisions. Do your own research, understand the risks, and consult qualified professional advisers before making financial, legal, tax, or trading decisions. Structure does not provide personalized investment advice and does not guarantee any strategy outcome, return, or level of performance.

