Limit Order Book Transformers: Market Microstructure As A Representation Problem
Time to read:
15min
A recent Frontiers in Artificial Intelligence paper, LiT: Limit Order Book Transformer, is worth reading because it treats the limit order book as a structured market-state object before treating it as a modeling input. The paper's contribution is not the mere substitution of a transformer for an older model family, but the claim that the geometry of the book, including side, depth, time, and measurement type, should be preserved explicitly in the representation passed to the model.
Experienced systematic traders already operate at this level of abstraction. The first bid and ask levels define the current executable boundary; deeper levels describe available displayed size, replenishment, and latent pressure; the bid and ask sides have different economic meanings; and a recent cancellation, trade, or size change near the best quote carries different information from a stale update deeper in the book. A model architecture that flattens or patches this object without respecting those distinctions has already made a microstructure assumption, whether or not the researcher writes that assumption down.
The LiT paper makes that assumption visible. It asks whether the now-standard CNN approach to limit order book modeling can be replaced by structured patches and self-attention, where the patches are designed around the market object rather than imported directly from image modeling. The result is not a trading system, and the paper should not be read as one; it is a useful research artifact because it pushes on a production-relevant question: how much short-horizon predictability comes from the model class itself, and how much comes from preserving the representation of the market state before the model begins learning?
The Order Book Is A State Process
A level-`n` order book snapshot can be written as a sequence of tuples:
Here `P` denotes price and `S` denotes displayed size resting at that price level. The paper uses price and volume terminology in places, but for order book data the more precise object is displayed size at a quote level; traded volume is a different measurement produced by executions.
The tuple at level `1` sits at the matching boundary. It is exposed to incoming marketable orders, cancellations, queue depletion, spread formation, and immediate adverse-selection information in a way that level `20` is not. Deeper levels still matter, but they matter through a different mechanism: they describe the market's displayed ability to absorb order flow before the best bid or best ask has to change.
The book through time is therefore closer to a state process than to a static feature table:`
Here `H` is book depth, `W` is the lookback window in snapshots, and `C` is the number of measurement channels. A channel is just one measured field stored over the same book grid. In LiT, one channel represents price and the other represents displayed size. The paper uses the top 20 bid and ask levels from Binance Level 2 data, so each timestamp contains price and displayed-size fields across both sides of the book; each training example uses the 64 most recent snapshots.
For a practitioner, the tensor notation matters only because it forces the representation problem into the open. Side, depth, time, and measurement type are separate coordinates of the market state, and collapsing them too early can remove exactly the information that makes the short-horizon problem tradable.
What LiT Changes
The usual deep-learning path for limit order book data has been CNN-based. DeepLOB is the canonical example: use convolutional layers to extract local spatial structure from the book, then use recurrent layers to model time. TransLOB adds transformer machinery, but still relies on convolutional feature extraction.
LiT removes the convolutional feature extractor and replaces it with structured patches plus transformer self-attention, followed by an LSTM head.
The architecture is roughly:
reconstruct the Level 2 book from exchange messages, meaning incremental updates are applied to a local book state so each timestamp has a coherent snapshot of the top book levels
retain the top bid and ask levels
split the `H x W x C` book tensor into structured patches
linearly project each patch into the model dimension (multiply the flattened patch by a learned weight matrix so every patch becomes a same-length vector the transformer can compare)
add learnable positional embeddings so the model can distinguish side and time (add trained location vectors so the model knows whether a patch came from the bid side, ask side, or a particular point in the lookback window)
process patches through transformer layers
pass the encoded sequence into LSTM layers
classify future mid-price movement as up, stable, or down
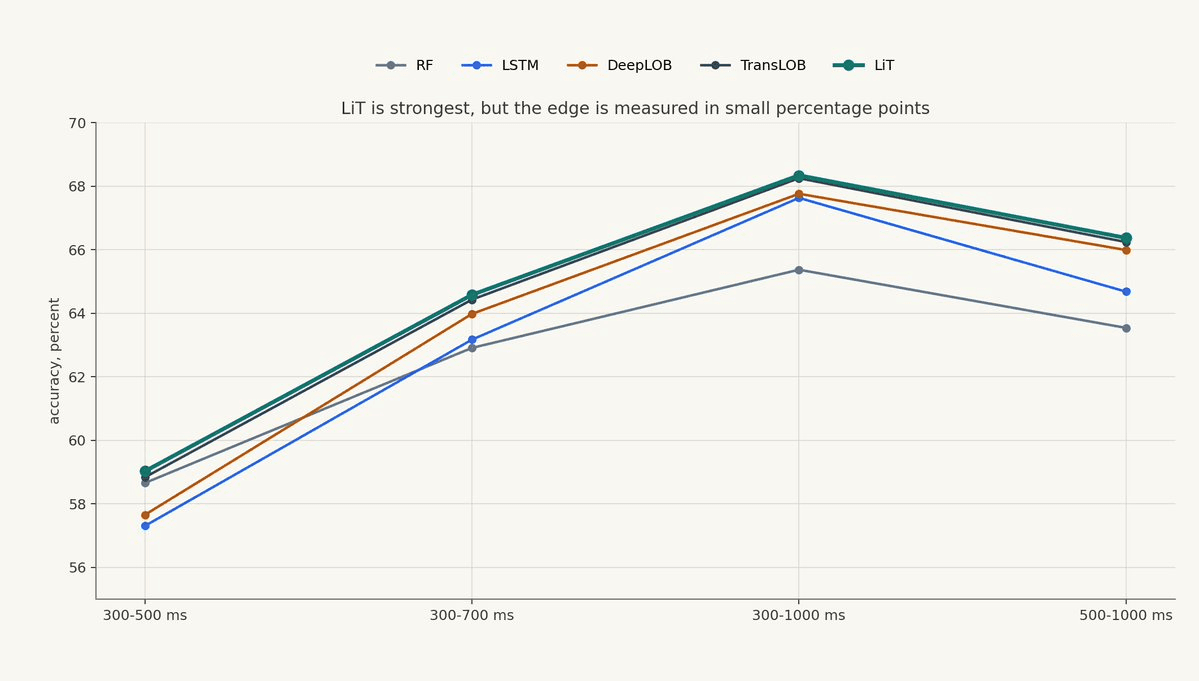
LiT is strongest across the paper's reported horizons. At the 300-500 ms horizon it reaches 59.03% accuracy, at 300-700 ms it reaches 64.58%, at 300-1000 ms it reaches 68.34%, and at 500-1000 ms it reaches 66.37%. The authors state that the models were implemented with comparable numbers of parameters, which helps make the comparison cleaner, but the economic question is not settled by parameter count or accuracy alone.
The edge over DeepLOB and TransLOB is often small. Whether the added architectural complexity is justified depends on what the model buys after the benchmark table: lower retraining cost, better adaptation, better calibration under regime drift, cleaner representation reuse, or a signal that remains profitable after execution constraints. If the only gain is a few tenths of a percentage point of classification accuracy and the system becomes harder to monitor, explain, retrain, or deploy, a production team would be right to hesitate. The paper's stronger claim is therefore not "LiT obviously wins"; it is that transformer-based LOB models can compete with CNN-based models when the patches respect market structure.
Structured Patches Are The Main Idea
The paper's most useful design choice is the patching scheme. A naive vision transformer cuts an image into small square patches because local neighborhoods in images often carry coherent information. The order book is not an image in that sense. A small square patch that mixes bid and ask rows, shallow and deep levels, or unrelated time steps may be convenient for the model while being incoherent as market data.
LiT uses structured patches with height `P_h` and width `P_w`. The height is chosen to preserve a coherent region of book depth, and the width is a short temporal window. The patch count is:
The design pressure is familiar from trading research. Pool too aggressively across time and the event sequence disappears; slice too narrowly across depth and the model loses information about displayed liquidity beyond the best bid and best ask. That deeper displayed liquidity matters because it changes how much order flow the book can absorb before prices must update, and it can reveal whether the visible best quotes are backed by broader depth or are sitting in a thin book.
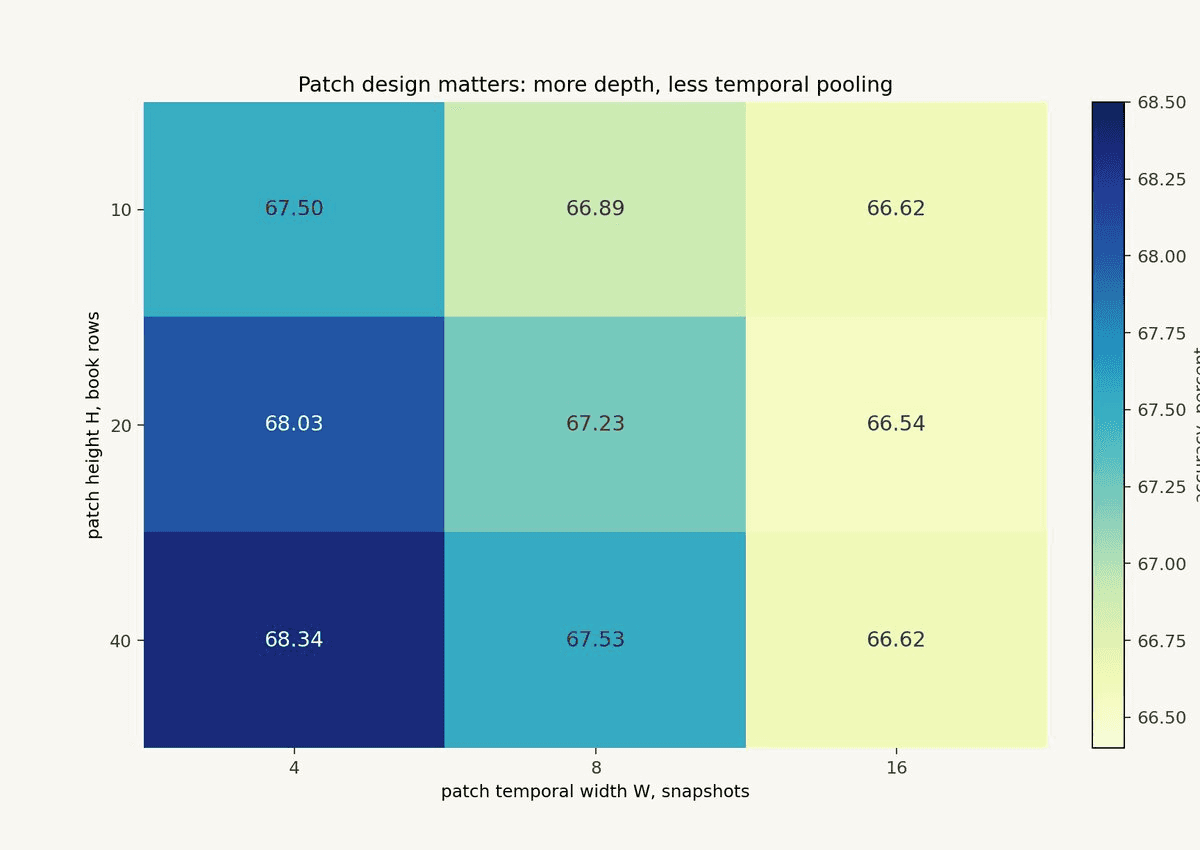
The ablation makes the point. For the 300-1000 ms horizon, the best reported patch configuration is `H=40, W=4`, with 68.34% accuracy. Narrower temporal patches outperform wider ones, and deeper spatial coverage helps. In market language, the model wants a broader view of the book while preserving high-frequency temporal resolution.
The practitioner value of this result is that it does not reduce to "larger model, better performance." The representation's geometry has measurable consequences, so the model's inductive bias should be shaped by how the order book evolves, not by whichever patch geometry happened to work on images.
Self-Attention And The LSTM Head
The self-attention mechanism computes relationships between patches through query, key, and value projections:
In practical terms, each patch becomes a token. A token might represent a side of the book over a short time interval, including prices and displayed sizes for a coherent region of depth. The attention layer lets each token compare itself with other tokens and form a weighted combination of the information that appears relevant for the prediction task.
For a limit order book, that is useful only if the tokens have microstructural meaning. A model may need to relate shallow ask depletion to deeper ask replenishment, bid-side depth to later mid-price movement, recent compression to a sudden imbalance, or a cancellation sequence to the probability that the best quote will change. A convolutional filter has a fixed local receptive field; attention can connect separated regions of the input, provided the model has enough data and the representation has not already destroyed the relevant distinctions.
The LSTM head is the second important design choice. LiT is not a pure transformer dropped onto book data. The transformer encodes relationships among structured patches, then the LSTM imposes a sequential state over those encoded representations before the softmax layer emits up, stable, or down. One way to think about the division of labor is that attention estimates relationships among book regions, while the LSTM keeps track of the order in which those encoded relationships arrive. That matters because a book state is not only a collection of levels; it is a path of additions, cancellations, executions, and quote changes.
The Target Is Mid-Price Movement, Not A Strategy
The paper defines future movement using average future mid-price change over several short windows, then classifies the outcome with a small threshold. In plain terms, it asks whether the future mid-price path is up, stable, or down over horizons such as 300-500 ms and 300-1000 ms.
The target can be summarized as:
The classification labels are then determined by whether `Delta p_t` exceeds a threshold, falls below the negative threshold, or remains inside the stable band.
As a research target, this is coherent; as a trading objective, it is incomplete. A mid-price movement label does not know whether the strategy could have joined the queue, crossed the spread, held inventory, avoided adverse selection, or exited without changing the best bid or best ask. It also does not know whether the predicted move is large enough to survive taker fees, maker rebates, latency, partial fills, self-trade prevention, venue throttles, borrow or funding, and signal decay before execution.
At trading firms, this is where model work has to pass through replay. A classifier can be directionally informative and still be unusable if the forecast arrives after the queue has moved, if the positive class corresponds to moves too small to trade, or if the model is mostly detecting conditions under which the next executable fill is adverse.
Fine-Tuning Is The Production-Relevant Result
The benchmark table is useful, but the fine-tuning result may be the more important part of the paper. LiT is pre-trained on September 2024 data, then evaluated on October, November, and December. In the zero-shot setting, the model trained on September is applied directly to later months without any additional training on those later months. This tests whether the learned representation transfers unchanged into a new market period.
Performance degrades as the model moves away from the training period. Fine-tuning only the final dense layers on recent data restores performance and beats training from scratch in the reported experiment.
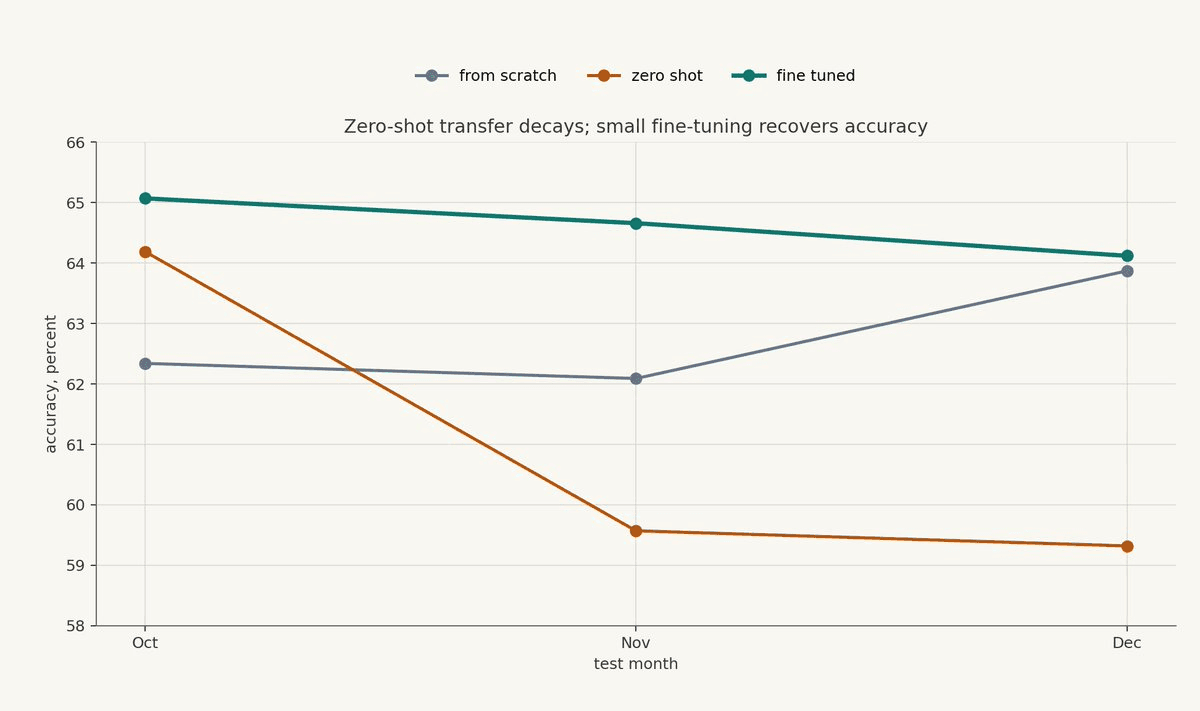
The interpretation is that different parts of the model may be learning different kinds of objects. The early layers can learn reusable representations of book geometry: how side, depth, displayed size, and time interact in a high-frequency book. The final layers then learn the current mapping from that representation to the label. When market conditions shift, the geometry may remain partially reusable while the mapping from representation to future mid-price movement becomes stale.
This matches how short-horizon models often behave in practice. A signal can continue to describe something real about the book while its calibration changes because spread, participation, volatility, fee pressure, queue behavior, or venue mix has changed. Fine-tuning only the final layers is a way of saying: keep the lower-level representation, update the decision boundary.
The operational implication is not "fine-tune every model and go live." Model governance should separate representation stability from decision calibration. A desk should ask which layers or parameters encode slow-moving book geometry, which encode recent regime mapping, how often the mapping must be refreshed, and whether the refresh procedure can be replayed causally without using information from the test window.
The Deployment Gap
The paper is useful research, but practitioners should read it through the deployment gap.
First, the reported metric is classification accuracy, with class-frequency normalization. Accuracy is useful for comparing model classes, but a strategy cares about conditional return after execution constraints. The class with the highest predictive accuracy may not be the class with the highest economic value.
Second, the dataset is Binance Level 2 data from September through December 2024. That gives the paper high-frequency scale, but it does not establish asset-class invariance, venue invariance, or invariance across matching rules. A model trained on one venue's book may learn venue-specific mechanics as much as universal microstructure.
Third, timestamps with no mid-price change are excluded. That choice makes the forecasting problem more event-like, which may be reasonable for research, but it changes the relationship between clock time, market inactivity, and strategy opportunity. For deployment, periods without mid-price changes still matter because capital, inventory, queue position, and order placement decisions continue to exist.
Fourth, the paper uses raw price and displayed-size fields. The authors note that additional high-frequency features such as order imbalance may improve performance. A practitioner would also care about queue imbalance, spread state, cancellation intensity, realized volatility, trade prints, replenishment, fill probability, and venue-specific order-flow mechanics.
These constraints define the boundary between a promising signal architecture and a trading system.
How This Maps Into Strategy Architecture
A LiT-style model belongs in the `data, computations, and signals` layer of a trading system. It consumes tick-level book data, computes a learned representation, and emits a directional probability or class score. That score is not a target position by itself.
In Structure terms, the signal still has to enter deterministic strategy logic. The state machine decides whether the signal is active, stale, uncertain, outside its training domain, or contradicted by cost and liquidity state. Each state resolves to target positions, and the executor manages orders to achieve those target positions outside the strategy logic.
The assignment can be written as:
Here `y_t hat` is the LiT-style model output, `c_t` is the current cost and execution state, `z_t` is the broader market regime or uncertainty state, and `theta` is the parameter set. The architectural move is to promote the learned model to one component in an auditable decision loop rather than treating it as an autonomous trading policy.
For algo traders, that separation is the reason the paper is worth reading. The model is an estimator of short-horizon book state. The strategy is the machinery that decides when that estimator is allowed to change target positions.
The Takeaway
The LiT paper should be read as a representation-learning paper for market microstructure, not as evidence that transformers should replace every CNN in short-horizon trading. The reported edge is measured, the deployment problem remains larger than the benchmark problem, and the key production question is whether the representation improves the full decision loop after cost, latency, fill probability, and retraining governance are included.
Its most useful claim is architectural: the order book is a structured state process; the patching scheme is an assumption about market geometry; attention estimates relationships among coherent book regions; and fine-tuning suggests that representation and calibration should be governed separately. Serious systematic trading research should keep moving toward better alignment between the object being modeled and the strategy machinery that eventually acts on it, rather than toward model architecture as fashion.
Not Financial Advice
The content above is for general educational and informational purposes only. It is not financial, investment, trading, legal, tax, accounting, or other professional advice, and it is not a recommendation, offer, or solicitation to buy, sell, hold, or use any asset, strategy, protocol, venue, or financial product.
Trading and automated strategies involve substantial risk, including the possible loss of principal. Crypto assets and DeFi markets can be highly volatile, illiquid, technically complex, and subject to execution, smart contract, custody, regulatory, and counterparty risks. Past performance, backtests, simulations, or examples do not guarantee future results.
You are responsible for your own decisions. Do your own research, understand the risks, and consult qualified professional advisers before making financial, legal, tax, or trading decisions. Structure does not provide personalized investment advice and does not guarantee any strategy outcome, return, or level of performance.

